数据库有关联语句,可以方便地进行对齐连接运算,但有时数据是存储在文本文件中的,用JAVA直接计算需要写大量循环语句才能实现,代码繁琐且运行低效。使用集算器来辅助Java编程,可以方便高效地解决此类问题。下面我们通过例子来看一下具体作法。
文本文件emp.txt存储着员工信息,EId等于1的员工不在该文件中。文本文件sOrder.txt存储着订单信息,其SellerId字段和emp中的EId字段相对应,SellerId等于2的订单不在该表中。部分源数据如下:
emp.txt:

sOrder.txt:
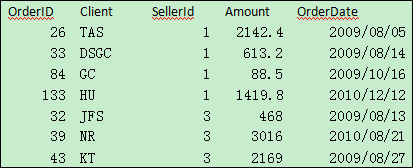
现在需要将emp的Name、Dept、Gender这三个字段对齐到sOrder中,计算结果输出到新文件中。期望的计算结果如下:

集算器代码:

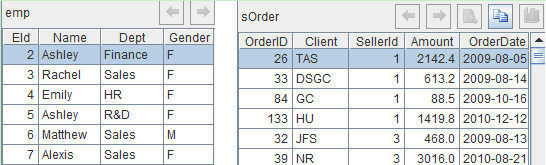
A1格和A2格分别从文本文件中读取数据,并存入两个变量emp和sOrder。这里使用了函数import,其默认的列分割符是tab,函数选项@t表示将第一行读为字段名。由于例子中只需要emp.txt中的部分字段,因此A1需要以字段名做参数。计算完成后,emp和sOrder的值如下图:
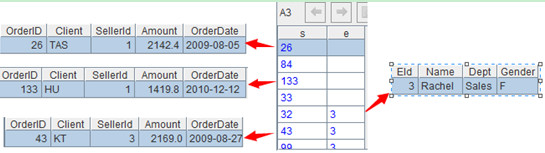
A3:=join@1(sOrder:s,SellerId;emp:e,EId)。函数join执行连接运算,并将两个表改名为s和e。其中函数选项@1表示左连接,即例子中的要求:将emp对齐到sOrder中。计算后结果如下:

点击蓝色链接可以看到具体的记录,如下:
右连接只是交换对齐的位置,同样可以用集算器来实现。比如将sOrder按照emp对齐,只需要在代码中交换两者的顺序,即=join@1(emp:e,EId;sOrder:s,SellerId),计算结果如下:

全连接也很容易实现,只需要使用函数选项@f,代码是:join@f(sOrder:s,SellerId;emp:e,EId),计算结果如下:
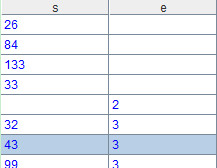
连接运算共有四种,除了上面提到的左连接、右连接、全连接,还有内连接。函数join默认执行内连接,代码是=join(sOrder:s,SellerId;emp:e,EId),计算结果如下:
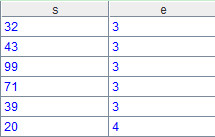
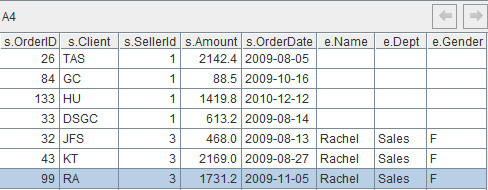
回到例子中,A4:=A3.new(s.OrderID, s.Client, s.SellerId, s.Amount, s.OrderDate, e.Name, e.Dept, e.Gender)。这句代码从连接的表中取得需要的字段,组成新的结构化二维表格,计算结果如下:
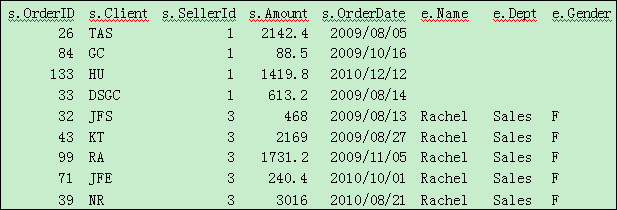
对齐的工作已经完成,下面将数据输出到新的文件,代码为:=file(“E: \\result.txt”).export@t(A4)。
函数export默认使用tab作为列分割符,函数选项@t表示将字段名输出在第一行。打开result.txt,可以看到内容如下:
上述脚本已经完成了所有的对其输出工作,接下来只需在JAVA代码中调用即可。
//建立esProc jdbc连接
Class.forName(“com.esproc.jdbc.InternalDriver”); con= DriverManager.getConnection(“jdbc:esproc:local://”); //调用esProc,其中test是脚本文件名 st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test()”); //执行esProc存储过程 st.execute();只要执行上述JAVA代码,emp就会对齐到sOrder中,并将计算结果输出到result.txt文件。
下面将例子稍作改动:按动态的时间段查询sOrder中的数据,并执行同样的对齐操作,最后直接将结果返回JAVA。为了实现这个例子,集算器需要定义两个参数,分别是begin和end,代表起止时间。集算器代码如下:
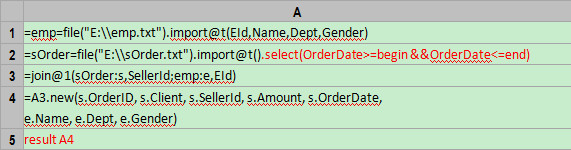
红色部分为改动的代码。
A2:通过函数select对sOrder进一步过滤,过滤条件为JAVA传来的起止时间,即@begin和@end。
A5:将A4中的计算结果输出到JDBC接口。
JAVA代码也需要进行相应的改动,以便传入参数,并获取计算结果。代码如下:
Class.forName(“com.esproc.jdbc.InternalDriver”);
con= DriverManager.getConnection(“jdbc:esproc:local://”); st =(com.esproc.jdbc.InternalCStatement)con.prepareCall(“call test(?,?)”); st.setObject(1,startTime); st.setObject(2,endTime); st.execute(); ResultSet set = st.getResultSet();